echo 1 > /proc/sys/net/ipv4/ip_forward
kubeadm reset rm -rf /etc/kubernetes rm -rf /var/lib/etcd/ rm -rf $HOME/.kube systemctl stop kubelet systemctl stop docker rm -rf /var/lib/cni/ rm -rf /var/lib/kubelet/* rm -rf /etc/cni/ ifconfig cni0 down ifconfig flannel.1 down ifconfig docker0 down ip link delete cni0 ip link delete flannel.1 systemctl start docker
这个问题一般出现在不同内网网段下的节点进行集群时,同一内网网段下的节点。
这个是因为 master 节点的 IP 地址和网卡绑定的 IP 地址不一致。例如一台云服务器,它的网卡绑定的是内网地址:192.168.102.130,不是直接绑定它的公网地址:182.160.13.60。
| 节点 | 内网 IP | 公网 IP | | --- | --- | --- | | master | 192.168.102.130 | 182.160.13.60 | | node01 | 172.31.0.106 | 49.10.98.123 |
对于 Master 节点,需要把 node01 节点的内网 IP 通过 iptables 重定向到 node01 节点的公网 IP,有多少个不同网段的 node 节点就需要重定向多少次,同一网段的不需要。
iptables -t nat -A OUTPUT -d 172.31.0.106 -j DNAT --to-destination 49.10.98.123
Master 节点在 kubeadm init 指定的 apiserver-advertise-address 地址是服务器的公网地址时,即使 /etc/hosts 把 master 指向了服务器的公网IP,依旧会报获取节点 master 失败的错误,正确方法是:kubeadm init 指定的 apiserver-advertise-address 地址使用服务器网卡的内网地址。
kubeadm init --kubernetes-version=1.23.6 \ --apiserver-advertise-address=192.168.102.130 \ --image-repository registry.aliyuncs.com/google_containers \ --service-cidr=10.10.0.0/16 --pod-network-cidr=10.122.0.0/16
对于 Node 节点,需要使用 iptables 将 Master 节点的内网 IP 重定向到 Master 节点的公网 IP:
iptables -t nat -A OUTPUT -d 192.168.102.130 -j DNAT --to-destination 182.160.13.60
把 master 节点的内网 IP 重定向到 master 节点的公网 IP,然后再进行 kubeadm join,kubeadm join 使用的 IP 地址是 master 节点的内网 IP,如下:
kubeadm join 192.168.102.130:6443 --token 1hm20n.i8f9e80iltt2el7g \ --discovery-token-ca-cert-hash sha256:6f17183b0d724cab2adab6e8e6b96a317a5238411aeba87de7b249a4015f769e
需要在docker指定访问的组,然后重启docker,重置kubernetes,然后重新初始化。
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://t50s9480.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
kubeadm reset
rm -rf /etc/kubernetes
rm -rf /var/lib/etcd/
rm -rf $HOME/.kube
kubeadm init --kubernetes-version=1.23.6 \
--apiserver-advertise-address=192.168.102.130 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.10.0.0/16 --pod-network-cidr=10.122.0.0/16
[INFO][7859] confd/health.go 180: Number of node(s) with BGP peering established = 0 calico/node is not ready: BIRD is not ready: BGP not established with 10.0.20.14
这个一般是因为服务器或者虚拟机的 TCP 179 端口没开,开启端口后正常。
kubectl delete -f calico.yaml
kubectl get node kubectl delete node 节点名称
kubectl label node 节点名称 node-role.kubernetes.io/worker=worker
查看状态为 NotReady 节点的 /etc/cni/net.d/ 目录下为空
cd /etc/cni/net.d/
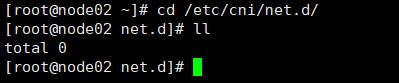
查看状态为 Ready 节点的 /etc/cni/net.d/ 目录下存在 10-calico.conflist、calico-kubeconfig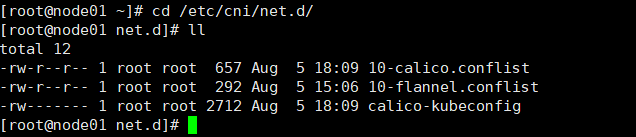
复制状态为 Ready 节点的 /etc/cni/net.d/ 目录下的 10-calico.conflist、calico-kubeconfig 到状态为NotReady节点的 /etc/cni/net.d/ 目录下
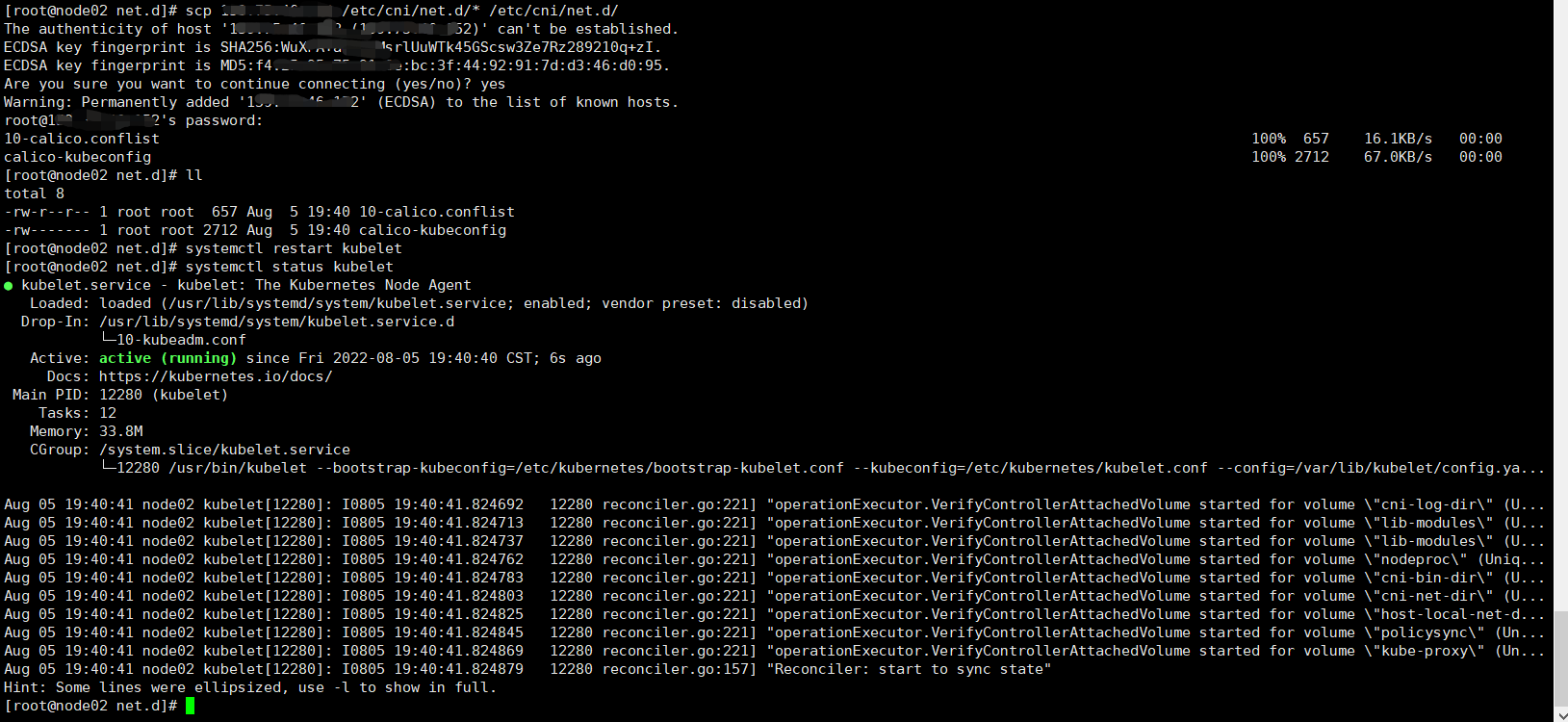
重启状态为 NotReady 的节点
再次查看节点状态,已正常
scp node01节点的IP:/etc/cni/net.d/* /etc/cni/net.d/ systemctl restart kubelet systemctl status kubelet

[root@node02 net.d]# docker logs 1344a4e681ef time="2022-08-05T11:49:14Z" level=info msg="Running as a Kubernetes pod" source="install.go:140" 2022-08-05 11:49:16.607 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/bandwidth" 2022-08-05 11:49:16.608 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/bandwidth 2022-08-05 11:49:16.677 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/calico" 2022-08-05 11:49:16.677 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/calico 2022-08-05 11:49:16.738 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/calico-ipam" 2022-08-05 11:49:16.738 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/calico-ipam 2022-08-05 11:49:16.741 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/flannel" 2022-08-05 11:49:16.741 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/flannel 2022-08-05 11:49:16.744 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/host-local" 2022-08-05 11:49:16.744 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/host-local 2022-08-05 11:49:16.814 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/install" 2022-08-05 11:49:16.814 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/install 2022-08-05 11:49:16.818 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/loopback" 2022-08-05 11:49:16.818 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/loopback 2022-08-05 11:49:16.822 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/portmap" 2022-08-05 11:49:16.822 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/portmap 2022-08-05 11:49:16.825 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/tuning" 2022-08-05 11:49:16.826 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/tuning 2022-08-05 11:49:16.826 [INFO][1] cni-installer/<nil> <nil>: Wrote Calico CNI binaries to /host/opt/cni/bin 2022-08-05 11:49:16.852 [INFO][1] cni-installer/<nil> <nil>: CNI plugin version: v3.23.3 2022-08-05 11:49:16.852 [INFO][1] cni-installer/<nil> <nil>: /host/secondary-bin-dir is not writeable, skipping W0805 11:49:16.852222 1 client_config.go:617] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work. 2022-08-05 11:49:46.853 [ERROR][1] cni-installer/<nil> <nil>: Unable to create token for CNI kubeconfig error=Post "https://10.10.0.1:443/api/v1/namespaces/kube-system/serviceaccounts/calico-node/token": dial tcp 10.10.0.1:443: i/o timeout 2022-08-05 11:49:46.853 [FATAL][1] cni-installer/<nil> <nil>: Unable to create token for CNI kubeconfig error=Post "https://10.10.0.1:443/api/v1/namespaces/kube-system/serviceaccounts/calico-node/token": dial tcp 10.10.0.1:443: i/o timeout [root@node02 net.d]#
出现这种问题的原因是因为创建 k8s 集群的时候,初始化主节点时网络地址段出现重叠导致的,如下面的初始化命令,API Server 和 Service 的网段出现重叠。
kubeadm init --kubernetes-version=1.23.6 \ --apiserver-advertise-address=10.0.20.14 \ --image-repository registry.aliyuncs.com/google_containers \ --service-cidr=10.10.0.0/16 --pod-network-cidr=10.122.0.0/16
彻底解决只能重新安装k8s集群
停止服务
kubeadm reset
删除残余文件
rm -rf /etc/kubernetes rm -rf /var/lib/etcd/ rm -rf $HOME/.kube
重新初始化主节点
初始化时注意各网段的设置,不能重复
kubeadm init --kubernetes-version=1.23.6 \ --apiserver-advertise-address=10.0.20.14 \ --image-repository registry.aliyuncs.com/google_containers \ --service-cidr=100.10.0.0/16 --pod-network-cidr=110.122.0.0/16
